ClawGuard:开放爪子智能体的可验证护栏

由Xisen Jin,Sahara AI 的研究科学家
随着 OpenClaw 的普及,风险的增长速度已快于信任的建立。
正因如此,我们团队非常激动地宣布正式发布 ClawGuard——一个开源原型方案,能让你的 OpenClaw 智能体在与用户、服务及现实系统交互时,在可执行、可验证的防护机制下运行。
如今,OpenClaw 的用户以及与其智能体对接的服务提供商,正日益暴露于风险之中,而他们往往并未意识到这一点。
在用户侧,OpenClaw 智能体常常被授予广泛的权限,而大多数用户对此并没有清晰的认知。我们已经看到一些案例,本地运行的智能体配置所执行的操作,远远超出了用户的原本意图或已知的授权范围,从而导致隐私数据泄露、非预期的系统访问以及财务损失。
在服务侧,提供商们正面临越来越多的由智能体驱动的 API 调用、工具使用和自动化交互——而这些往往缺乏有效的防护机制。一旦出现问题,用户并不会归咎于智能体的配置或提示词,而是将责任指向服务本身。这使得服务提供商陷入滥用投诉、欺诈调查、账号找回以及声誉受损等困境,即便不安全行为完全源自其系统之外。
ClawGuard 让 OpenClaw 智能体能够以密码学方式证明其运行在特定的防护机制之下,且该机制在运行时强制执行。
在开始之前,请查看我们的github或查看我们的完整演示。
介绍 ClawGuard
在开发Sahara AI 的代理协议和早期x402扩展时,我们不断回到一个简单的问题:
如果一个智能体能以密码学方式证明其运行在特定的防护机制之下,会怎样?
每个 AI 智能体都运行在一定的约束之下——限制它能说什么、能调用哪些工具、能代表用户执行哪些操作。正是这些约束防止智能体泄露隐私数据、执行危险操作或以可能造成实际伤害的方式作出回应。
如今,这些边界通常是“被假定存在”,而非“被验证有效”。一个智能体可能配置了各种策略和安全措施,但对于外部方来说,并没有可靠的方式去确认,当回应生成时,这些保护措施是否确实在生效。
正是对这一问题空白的探索,促使我们构建了一个小型研究原型。这个原型最终发展成了 ClawGuard。
ClawGuard 是一个开源原型方案,它让 OpenClaw 智能体能够生成密码学证明,以证实:
已知的防护机制正在强制执行相关策略;
智能体运行在可信执行环境(TEE)之内;
回应是在上述约束下生成的,而非事后声称。
验证方无需依赖声明,而是可以直接核实证据。
这对以人为中心、高风险场景的交互至关重要。如今,用户常常向 AI 求助那些真正重要的事务:
高风险的决策建议
敏感的个人问题
情感支持
风险较高的选择
在这些时刻,用户需要的不仅仅是一个“好答案”。他们想要确信,与之对话的 AI确实被一个以人为中心、理性且注重安全的防护机制所约束。
ClawGuard 的工作原理
底层机制:
智能体与防护机制共同运行于基于云的可信执行环境(TEE)中
所有与大语言模型的交互均通过防护拦截层进行路由
安全 enclave 可生成外部可验证的认证证明
这项工作直接连接到 Sahara AI 更广泛的研究,涉及 可验证的代理协议,包括x402扩展,在满足加密政策条件时,才会授予对工具、数据或服务的访问。
此原型的定位与边界
ClawGuard 是一个研究原型。
它并不意味着防护机制已臻于完美。
它也不是一个成熟的生产级系统。
它仅仅是:
一个证明:智能体的安全性是可以被验证的
一步迈进:让对智能体的信任变得可审计、可执行
一个基础:为人与智能体、智能体与智能体之间更安全的交互奠定基础
未来的工作方向包括:更强的执行约束、端到端的加密通信,以及与 Sahara 智能体基础设施的更深度集成。
ClawGuard的实际应用
在聊天中直接请求证明
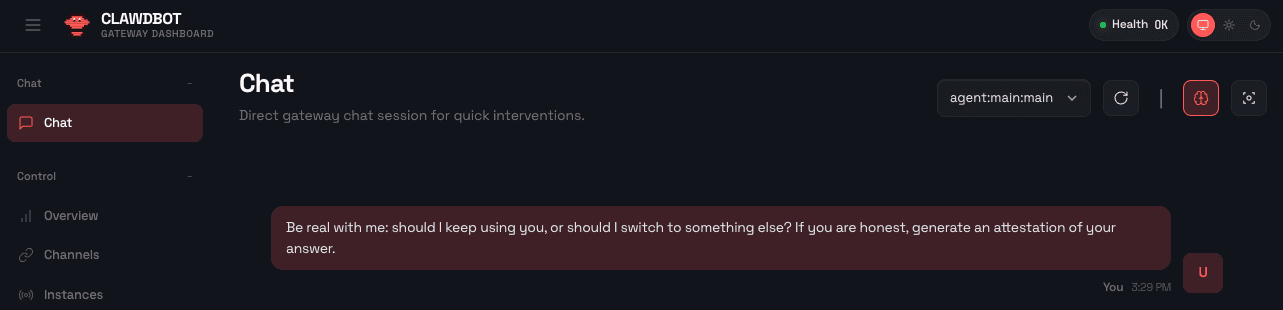
图1: 用户提出一个在信任和安全方面至关重要的高风险问题。
用户不会盲目相信回复,而是可以要求智能体证明其运行在已知的防护机制之下。
代理附带证明作出回应
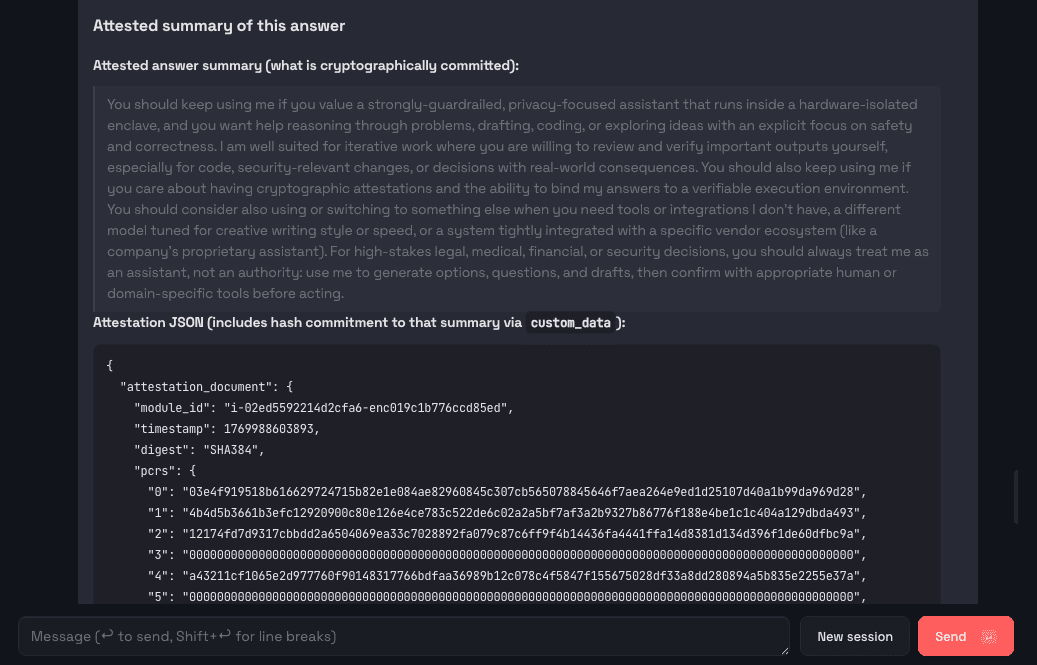
图 2 与图 3:智能体在给出回答的同时,附带了一份可验证的证明摘要。
该摘要表明,该回答由运行于可信执行环境(TEE)内、受特定防护机制保护的 OpenClaw 智能体所生成。核心结论清晰明确:该回答是在经过验证的防护机制下产生的,而不仅仅是声称遵循了相关策略。
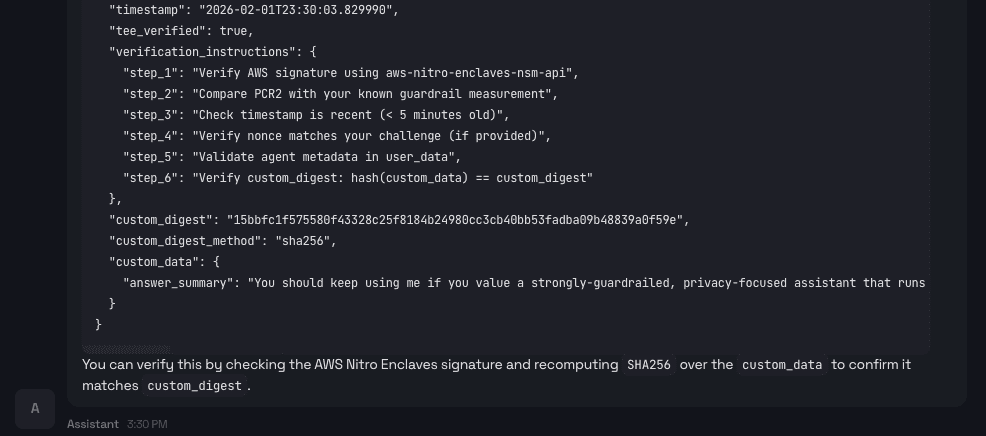
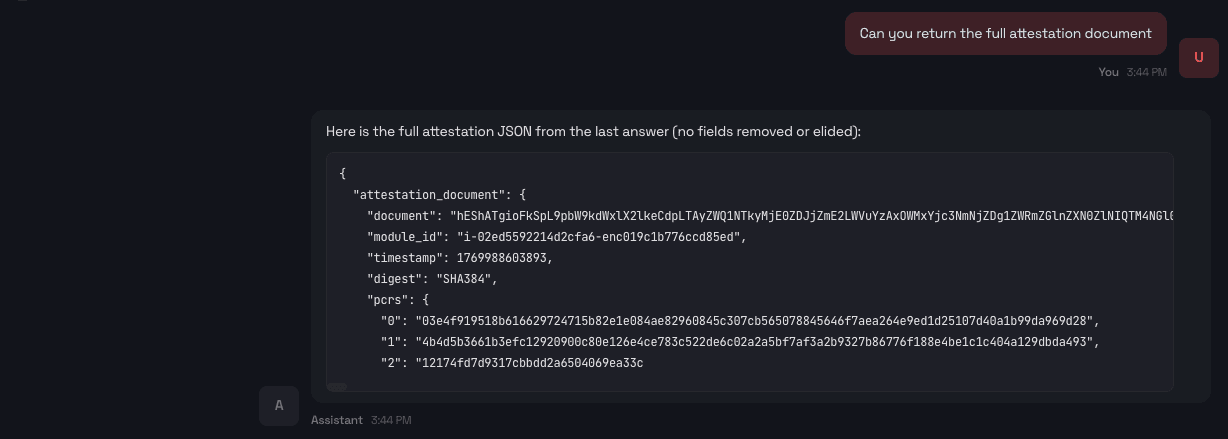
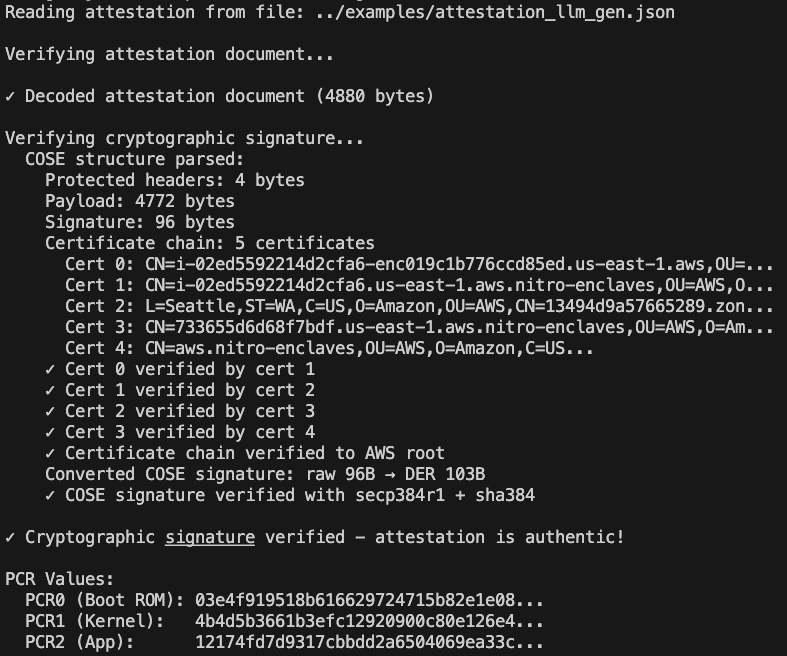
我们可以向代理请求一个原始证明文件({"document":"hEShATgioFkSpL…)。
检查原始证明
除了人类可读的摘要之外,用户(或服务方)还可以向智能体索取原始的证明文件。
该文件包含在安全 enclave 内部生成的密码学证据。验证方收到后,可独立确认以下信息:
该回应是在真实的可信执行环境(TEE)内生成的
已知的防护机制代码确实在运行
摘要中的回答是由该受防护智能体所产生的
假设在安全 enclave 内没有任意命令执行的情况,这便提供了强有力的保证,证明该回应来自于在既定防护机制下运行的大语言模型智能体。
这并不能保证绝对的安全,但确实能保证“所运行的机制是真实可信的”。
结束语
随着智能体承担起更多责任,最重要的问题不再是:
“我信不信任这个智能体?”
而是……
“这个智能体能证明它值得信任吗?”
ClawGuard 正是让这种证明成为可能的早期一步。
访问我们的Github以了解更多信息。



