How Sahara AI Powered MIT's Breakthrough in Training AI Agents That Use Computers Like Humans

When an MIT research team needed to train AI agents capable of navigating real operating systems, they faced a problem no one else could solve. Sahara AI delivered one of the most comprehensive real-world human-computer interaction datasets ever built for agent training, powering OSGym, now the leading open-source infrastructure for training computer-use agents.
The promise of autonomous AI agents is real: agents that manage your calendar, handle your finances, do your research, and execute complex workflows on your behalf. Tools like Anthropic's Claude with computer use, OpenAI's Operator, and open-source projects like OpenClaw are already putting this capability in users' hands.
But there's a gap between "impressive demo" and "production-grade autonomy" that most of the industry is still struggling to close. Models break on multi-step tasks, lose context across applications, and fail to recover when something unexpected happens. Agents can follow a script. What they can't yet do reliably is think through a real workflow the way a human does like switching between apps, recovering from errors, navigating unfamiliar interfaces, chaining together actions without losing the thread.
The limiting factor here isn't model intelligence; It's training data. Most agent training still relies on synthetic environments or narrow sandboxes that don't reflect the messy, nonlinear way people actually work. Fixing this requires real human behavior, captured at scale, annotated with the depth to teach an agent not just what to do, but how to think. That’s the problem Sahara AI solved for MIT.
Sahara AI has spent years building and deploying agentic AI in live production environments for some of the world's leading enterprises. We know how agents break, why they fail under real-world conditions, and what training data actually needs to look like to make them reliable at scale. That depth of experience is exactly why MIT chose to partner with us.
What It Actually Takes to Train an AI Agent to Use a Computer Like a Human
Over nearly a year, Sahara AI executed one of the most ambitious, real-world multimodal data collection programs ever undertaken for computer use agent training. This kind of scale was only possible through Sahara AI's Data Services Platform, a global contributor network of 200,000+ pre-vetted labelers across 35+ countries spanning the full diversity of operating systems, workflows, and human behaviors that MIT's agents would need to master.
Our expert annotators captured high-fidelity interaction data across every major environment a computer-use agent would need to master in macOS, Windows, and Ubuntu workflows. This included everything from daily web usage across platforms, to coding applications and developer tools, and complex cross-application task sequences.

The resulting multimodal training data including UI screenshots, operation logs, step-level interaction sequences, and task context metadata. This data was then validated through a multi-layer QA framework achieving 88%–100% batch-level accuracy. No comparable public dataset existed for this data category. Sahara AI built one from scratch, at scale, in a compressed timeline.
This data became the training foundation for agents that would go on to power OSGym, the open-source infrastructure MIT built to scale computer-use agent training to thousands of parallel OS replicas.
Phase 2: Teaching Agents to Fail Better
Collecting training data was only half the equation. The next step was to systematically teach the agents where they went wrong and why.
Sahara AI designed a structured correction program covering a multitude of real-world websites across a wide range of daily-use categories. For every evaluated task, our team dissected each error to understand what went wrong. Each correction captured the agent's reasoning trace, categorized the error type (logic, navigation, misunderstanding, sequence), assessed the thought process, and mapped alternative optimal paths.
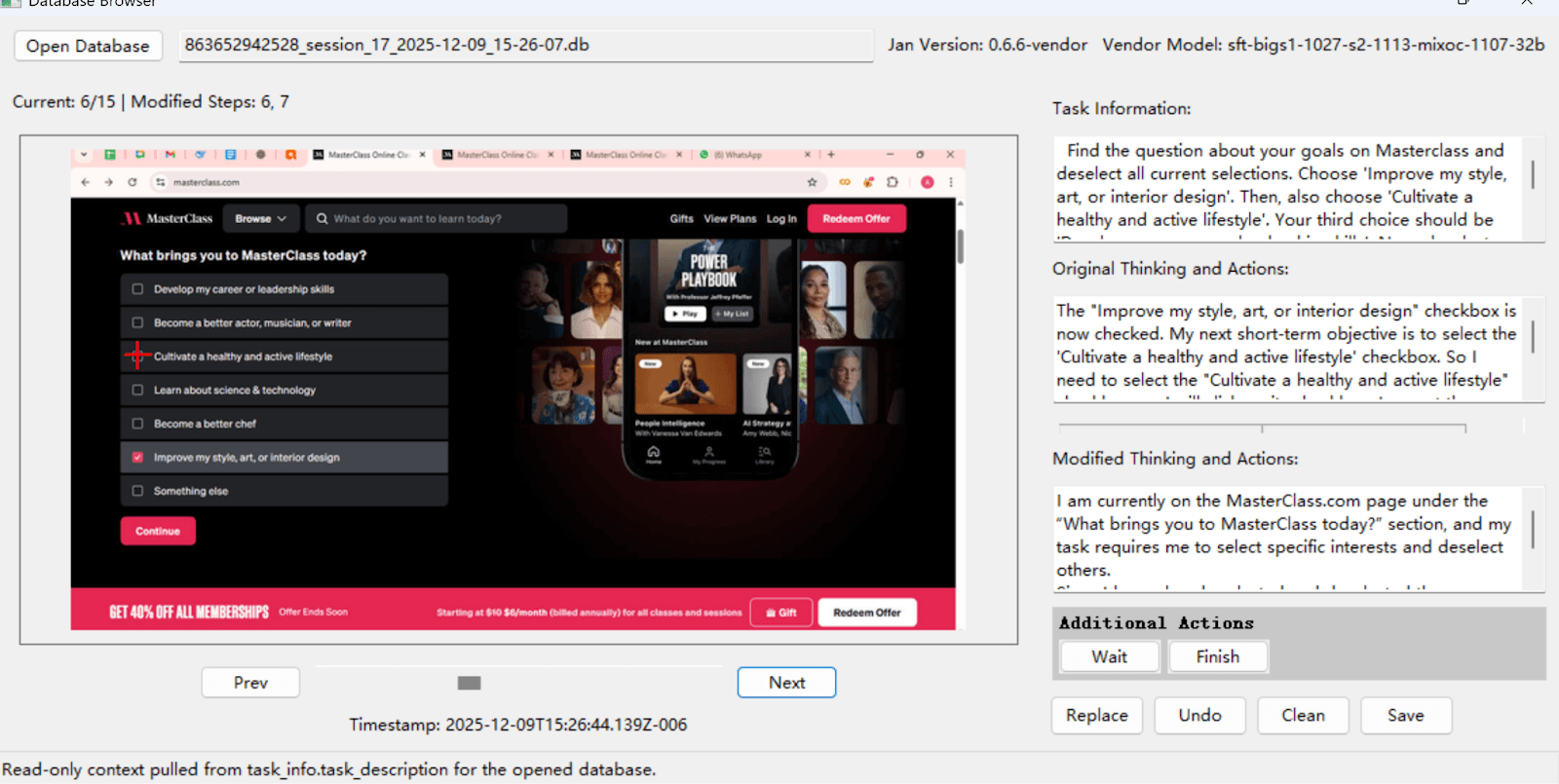
These structured steps were recorded, reviewed, and annotated, producing fine-grained supervision signals far beyond binary pass/fail. This is what transforms a mediocre agent into one that outperforms the state of the art.
Putting it Together to Create One of the Best Computer-Use Models
The two phases fed each other. Sahara collected real human data. MIT trained agents on it. Sahara evaluated and corrected the agents. MIT refined the models. Repeat.
What made this work wasn't the structure of this loop, but the expertise inside it. Every correction Sahara AI contributed came from a team that builds and deploys agentic AI in production. We weren't annotating behavior we'd read about. We were diagnosing failure modes we'd seen firsthand, in live environments, at enterprise scale. That's what made the supervision signals credible enough to actually move the model.
Over six months, the results compounded: reduced error rates on complex tasks, improved reasoning stability, better recovery from unexpected failures, stronger generalization to environments the agents had never encountered. On OSWorld, the standard benchmark for evaluating how well AI agents perform real computer tasks in live operating systems, scores improved by 30% after training.
The end product was OSGym, a system that parallelizes over a thousand OS replicas, generates 1,420 multi-turn trajectories per minute, and runs at just $0.20–$0.30 per day per replica. It's now fully open-source, with code on GitHub and datasets on HuggingFace.
This is the Sahara AI advantage. Our data capabilities exist because we build agentic AI, not the other way around. When we partner with enterprises and research labs, we bring years of production AI experience to every decision about what to collect, how to annotate it, and how to close the loop until the model performs.
As a member of the MIT research team summarized: "We would definitely work with Sahara AI again and recommend them to other research teams. Sahara delivered a large amount of high-quality data within a very short timeline, and has been very important in our training process."
Work With Sahara AI for Enterprise Data Services
From powering MIT's OSGym to Microsoft Research's MATHVISTA, Sahara AI has built one of the most advanced data services platforms in the industry.
Global Reach — 200,000+ pre-vetted labelers across 35+ countries, covering 45+ languages and dialects.
Multi-Modality Coverage — Text, images, video, and audio annotation.
Diverse Domain Expertise — From mathematical reasoning to agent behavior correction, finance, and beyond.
AI + Human Synergy — Combined AI-centered and human-in-the-loop labeling for speed and accuracy.
That's why Microsoft, Amazon, Snap, and MIT trust Sahara AI when accuracy, speed, and dependability are non-negotiable.
Learn more: https://saharaai.com/data-services-enterprise
About Sahara AI: Sahara AI is the agentic AI company dedicated to making AI more accessible and equitable. We build the core protocols, infrastructure, and applications that let personal agents anticipate and execute on your behalf. For this to work, infrastructure has to be trustworthy: verifiable execution, enforceable usage policies, and automatic value distribution across every tool, model, and service an agent touches. Sahara is building a growing suite of agent-powered applications on top of this foundation, including Sorin, your personal agent for global digital markets. Our solutions currently power AI agents and high-quality data for consumers, Fortune 500 enterprises, and leading research labs, including Microsoft, Amazon, MIT, Motherson, and Snap.



