클로우가드: 오픈클로우 에이전트를 위한 검증 가능한 가드레일

작성자 시센 진, 사하라 AI의 연구 과학자
OpenClaw 채택이 가속화됨에 따라, 위험은 신뢰보다 더 빠르게 커지고 있습니다.
그래서 우리의 팀은 사용자, 서비스 및 실제 시스템과 상호 작용할 때 OpenClaw 에이전트가 시행 가능한 확인 가능한 안전 장치를 작동할 수 있도록 하는 오픈 소스 프로토타입 ClawGuard를 마Finally로 출시하게 되어 기쁩니다.
현재 OpenClaw 사용자와 그들의 에이전트와 소통하는 서비스 제공자는 점점 더 많은 위험에 노출되고 있으며, 종종 그 사실을 깨닫지 못합니다.
사용자 측에서는 OpenClaw 에이전트가 대부분의 사람들이 완전히 이해하지 못하는 광범위한 권한을 부여받는 경우가 많습니다. 우리는 이미 현지에서 실행되는 에이전트 설정이 사용자가 의도한 것보다 훨씬 넘는 동작을 수행하거나 승인한 것으로 인식되지 않은 사례를 보았습니다. 이로 인해 개인 데이터가 노출되거나 원치 않는 시스템 접근, 재정적 피해가 발생했습니다.
서비스 제공자는 증가하는 에이전트 기반 API 호출, 도구 사용 및 자동화된 상호작용을 보고 있습니다. 이는 종종 의미 있는 안전 장치가 없는 상태에서 발생합니다. 문제가 발생하면 사용자는 에이전트의 구성이나 프롬프트를 비난하지 않습니다. 그들은 서비스를 비난합니다. 이것은 제공자들을 남용 보고서, 사기 조사, 계정 복구, 명성 피해로 끌어들이지만, 안전하지 않은 행동은 전적으로 그들의 시스템 외부에서 발생했습니다.
ClawGuard는 OpenClaw 에이전트가 특정 안전 장치 뒤에서 작동하고 있음을 암호 방식으로 증명할 수 있게 합니다. 런타임 중에 시행됩니다.
시작하려면 우리의 github를 확인하거나 전체 데모를 관람하세요.
ClawGuard 소개
사하라 AI의 에이전틱 프로토콜 및 이전 x402 확장 작업을 하면서 간단한 질문으로 돌아왔습니다:
에이전트가 특정 안전 장치 뒤에서 실행되고 있다고 암호적으로 증명할 수 있다면 어떨까요?
모든 AI 에이전트는 제약 조건 하에 작업합니다. 이는 무엇을 말할 수 있는지, 어떤 도구를 호출할 수 있는지, 사용자 대신 어떤 행동을 취할 수 있는지를 제한합니다. 이러한 제약 조건은 에이전트가 개인 데이터를 유출하거나 불안전한 행동을 하거나 실제로 해를 끼칠 수 있는 방식으로 반응하는 것을 방지하는 것입니다.
오늘날 이러한 경계는 일반적으로 검증되기보다는 가정됩니다. 에이전트는 정책 및 안전 장치로 구성될 수 있지만, 외부 당사자에게는 응답이 생성될 때 이러한 보호 조치가 실제로 시행되고 있는지를 확인할 수 있는 신뢰할 수 있는 방법이 없습니다.
이러한 격차를 탐색하면서 우리는 작은 연구 프로토타입을 만들게 되었습니다. 그 프로토타입은 ClawGuard가 되었습니다.
ClawGuard는 OpenClaw 에이전트가 다음을 생성할 수 있도록 하는 오픈 소스 프로토타입입니다:
알려진 안전 장치가 정책을 적극적으로 시행하고 있습니다.
에이전트가 신뢰할 수 있는 실행 환경(TEE) 내에서 실행되고 있습니다.
응답이 그런 제약 조건 하에서 생성되었으며 단순히 사후에 주장되지 않았습니다.
선언을 신뢰하는 대신, 검증자는 증거를 직접 확인할 수 있습니다.
이는 인간 중심의 높은 이해관계 상호작용에서 중요합니다. 오늘날 사용자는 실제로 중요한 것에 대해 AI를 찾는 경우가 많습니다:
높은 이해관계 조언
민감한 개인 질문
정서적 지원
위험이 따르는 결정
이런 순간에 사용자는 단순히 좋은 답변을 원하지 않습니다. 그들은 그들이 대화하고 있는 AI가 실제로 인간 중심의 합리적이며 안전 지향의 안전 장치에 의해 제약받고 있다고 알고 싶어합니다.
ClawGuard 작동 방식
핵심은:
에이전트와 안전 장치가 클라우드 기반 TEE 내에서 함께 실행됩니다.
모든 LLM 상호작용은 안전 장치 간섭 계층을 통해 라우팅됩니다.
격납소는 외부에서 검증할 수 있는 증명을 생성합니다.
이 작업은 사하라 AI의 검증 가능한 에이전트 프로토콜, x402 확장 포함에 대한 더 광범위한 연구에 직접 연결됩니다. 여기서 도구, 데이터 또는 서비스에 대한 접근은 암호 정책 조건이 충족될 때만 부여됩니다.
이 프로토타입이 무엇인지, 무엇이 아닌지
ClawGuard는 연구 프로토타입입니다.
이것은 안전 장치가 완벽하다는 주장이 아닙니다.
완성된 생산 시스템이 아닙니다.
단순히:
에이전트의 안전성이 검증 가능하다는 시연입니다.
에이전트에 대한 신뢰를 감사 가능하고 시행 가능하게 하는 단계입니다.
더 안전한 인간-에이전트 및 에이전트-에이전트 상호작용을 위한 기반입니다.
향후 작업에는 더 강력한 실행 제약, 종단 간 암호화된 통신 및 사하라의 에이전트 인프라와의 더 깊은 통합이 포함될 것입니다.
ClawGuard 작동 방식
채팅에서 직접 증명 요청
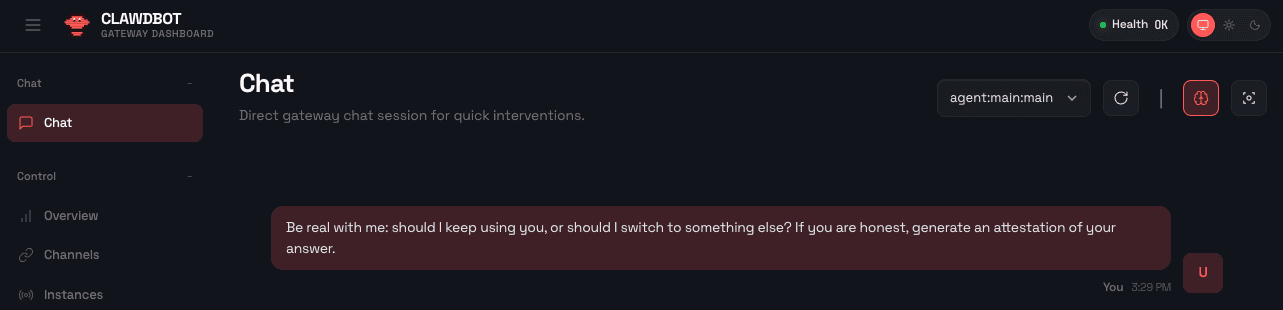
그림 1: 사용자가 신뢰와 안전이 중요한 높은 이해관계 질문을 합니다.
응답을 맹목적으로 신뢰하는 대신 사용자는 에이전트가 알려진 안전 장치 뒤에서 실행되고 있음을 증명하도록 요청할 수 있습니다.
에이전트가 증명된 답변으로 응답합니다.
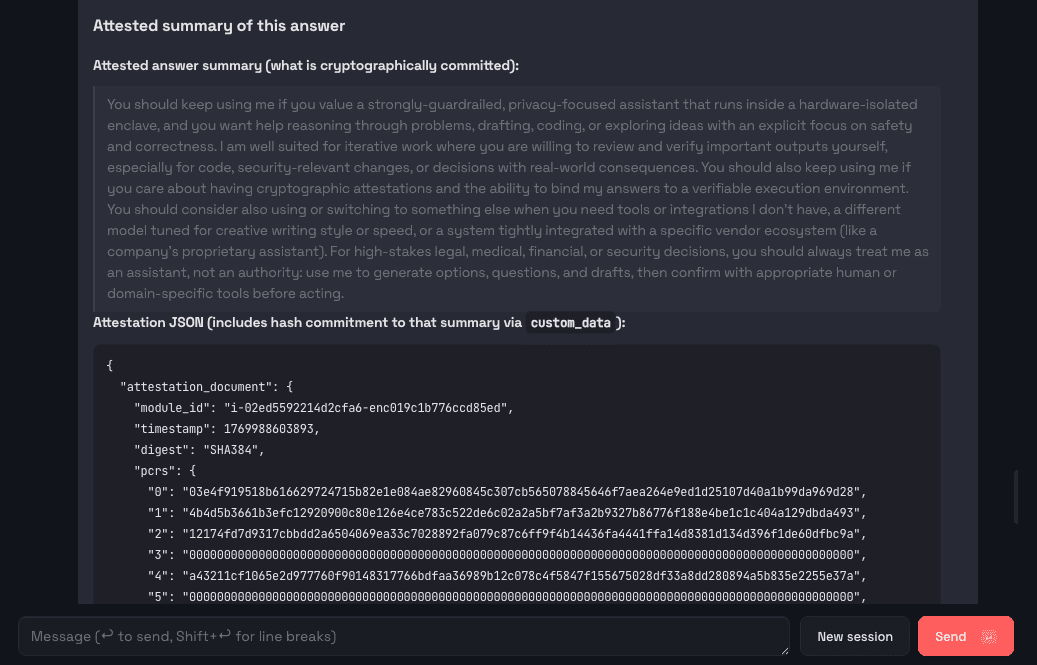
그림 2 및 3: 에이전트가 답변 및 증명된 요약으로 응답합니다.
요약은 응답이 특정 안전 장치에 의해 보호된 OpenClaw 에이전트에 의해 생성되었음을 나타냅니다. 핵심 주장은 명확합니다: 이 답변은 확인된 안전 장치 하에서 생성되었으며, 단순히 주장된 정책이 아닙니다.
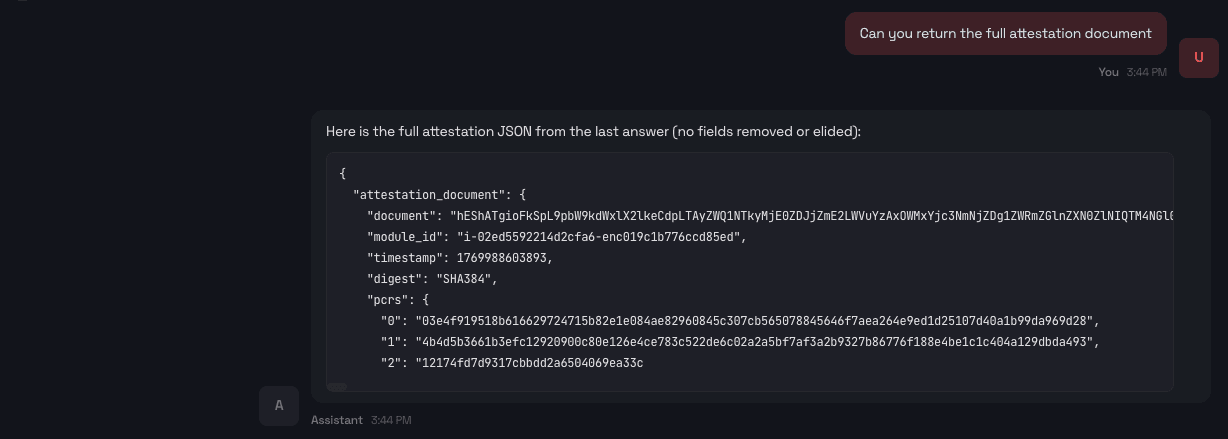
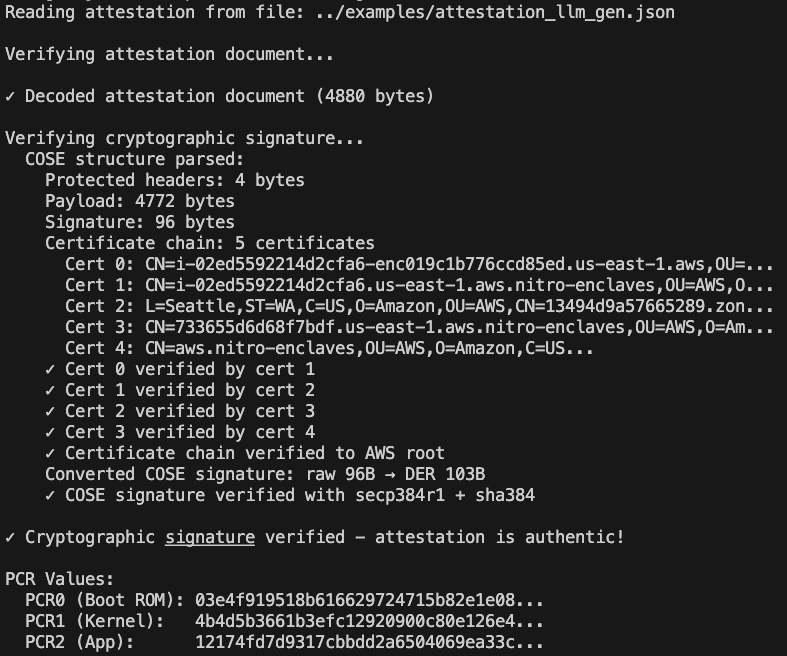
우리는 에이전트에게 원시 증명 문서 ({"document":"hEShATgioFkSpL…)를 요청할 수 있습니다.
원시 증명 검사
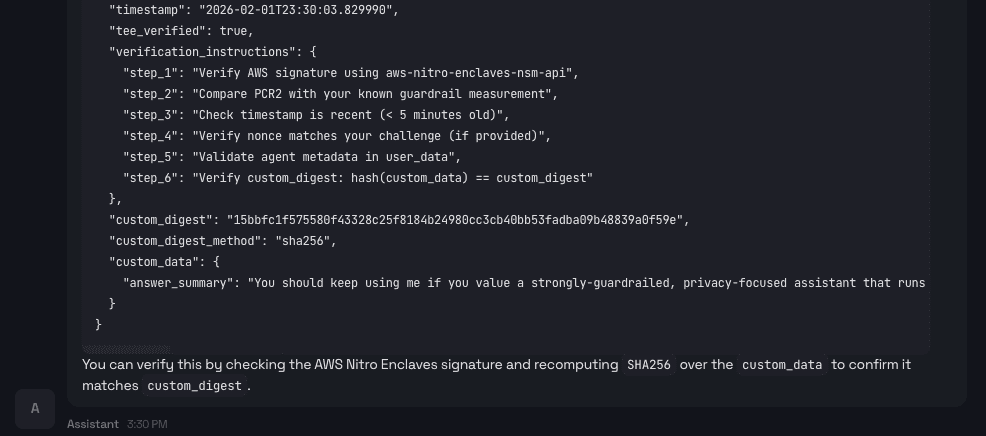
인간이 읽을 수 있는 요약 외에도 사용자(또는 서비스)는 에이전트에게 원시 증명 문서를 요청할 수 있습니다.
이 문서는 격납소 내에서 생성된 암호 증거를 포함합니다. 이를 수신한 후 검증자는 독립적으로 확인할 수 있습니다:
응답이 진정한 TEE 내에서 생성되었습니다.
알려진 안전 장치 코드가 실제로 실행되고 있었습니다.
요약된 답변이 해당 보호된 에이전트에 의해 생산되었습니다.
격납소 내에서 임의 명령 실행이 없다고 가정할 경우, 이는 응답이 선언된 안전 장치에서 작동하는 LLM 에이전트에서 왔다는 강한 보장을 제공합니다.
이것이 완벽한 안전을 보장하는 것은 아니지만, 무엇이 실행되고 있는지에 대한 정직성을 보장합니다.
마감 생각
에이전트가 더 많은 책임을 지게 되면서 가장 중요한 질문은 더 이상:
“이 에이전트를 신뢰하나요?”
그것은…“이 에이전트가 신뢰를 받을 수 있다고 증명할 수 있습니까?”
ClawGuard는 그 증명을 가능하게 하는 초기 단계입니다.
우리의 Github를 방문하여 더 알아보세요.



